- K-мерное дерево
-
K-мерное дерево Тип Многомерное дерево Двоичное дерево поиска Изобретено в 1975 году Изобретено Джон Бентли Временная сложность
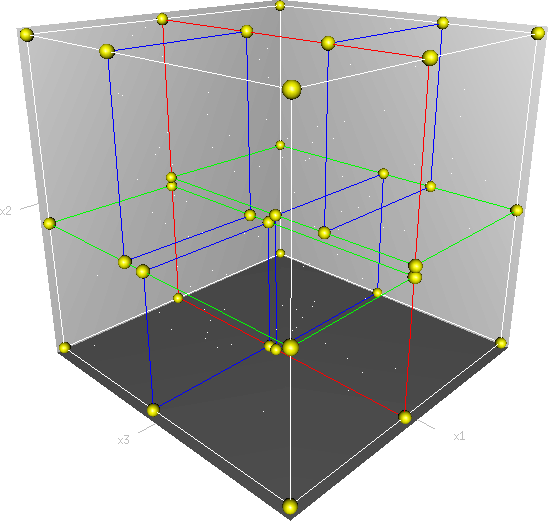
в О-символикеВ среднем В худшем случае Расход памяти O(n) O(n) Поиск O(log n) O(n) Вставка O(log n) O(n) Удаление O(log n) O(n)  Трёхмерное k-d дерево.
Трёхмерное k-d дерево.
В информатике k-d дерево (англ. k-d tree, сокращение от k-мерное дерево) — это структура данных с разбиением пространства для упорядочивания точек в k-мерном пространстве. k-d деревья используются для некоторых приложений, таких как поиск в многомерном пространстве ключей (поиск диапазона и поиск ближайшего соседа). k-d деревья — особый вид двоичных деревьев поиска.
Содержание
Математическое описание
K-мерное дерево — это несбалансированное дерево поиска для хранения точек из
 . Оно предлагает похожую на R-дерево возможность поиска в заданном диапазоне ключей. В ущерб простоте запросов, требования к памяти
. Оно предлагает похожую на R-дерево возможность поиска в заданном диапазоне ключей. В ущерб простоте запросов, требования к памяти  вместо
вместо  .
.Существуют однородные и неоднородные k-d деревья. У однородных k-d деревьев каждый узел хранит запись. При неоднородном варианте внутренние узлы содержат только ключи, листья содержат ссылки на записи.
В неоднородном k-d дереве
 при
при  параллельно оси
параллельно оси  -мерной гиперплоскости в точке
-мерной гиперплоскости в точке  . Для корня нужно разделить точки через гиперплоскость
. Для корня нужно разделить точки через гиперплоскость  на два по возможности одинаково больших множества точек и записать в корень, слева от этого сохраняются все точки у которых
на два по возможности одинаково больших множества точек и записать в корень, слева от этого сохраняются все точки у которых  , справа те у которых
, справа те у которых  . Для левого поддерева нужно разделить точки опять на новую «разделенную плоскость»
. Для левого поддерева нужно разделить точки опять на новую «разделенную плоскость»  , а сохраняется во внутреннем узле. Слева от этого сохраняются все точки у которых
, а сохраняется во внутреннем узле. Слева от этого сохраняются все точки у которых  . Это продолжается рекурсивно над всеми пространствами. Потом всё начинается снова с первого пространства, до того пока каждую точку можно будет ясно идентифицировать через гиперплоскость.
. Это продолжается рекурсивно над всеми пространствами. Потом всё начинается снова с первого пространства, до того пока каждую точку можно будет ясно идентифицировать через гиперплоскость.K-d дерево можно построить за
 . Поиск диапазона может быть выполнен за
. Поиск диапазона может быть выполнен за  , при этом
, при этом  обозначает размер ответа. Требование к памяти для самого дерева ограничено .
обозначает размер ответа. Требование к памяти для самого дерева ограничено .Операции с k-d деревьями
Структура
Структура дерева, описанная на языке C++:
Const N=10; // количество пространств ключей Struct Item{ // структура элемента int key[N]; // массив ключей определяющих элемент char *info; // информация элемента }; Struct Node{ // структура узла дерева Item i; // элемент Node *left; // левое поддерево Node *right; // правое поддерево }
Структура дерева может меняться в зависимости от деталей реализации алгоритма. Например, в узле может содержаться не один элемент, а массив, что повышает эффективность поиска.
- Анализ поиска элемента
Очевидно, что минимальное количество просмотренных элементов равно
 , а максимальное количество просмотренных элементов —
, а максимальное количество просмотренных элементов —  , где
, где  — это высота дерева. Остаётся посчитать среднее количество просмотренных элементов
— это высота дерева. Остаётся посчитать среднее количество просмотренных элементов  .
.![[x_0,x_1,x_2,...,x_n]](6716484c2576f6bdc0b3cff9cee6a574.png) — заданный элемент.
— заданный элемент.Рассмотрим случай
 . Найденными элементами могут быть:
. Найденными элементами могут быть:и так для каждого пространства ключей. При этом средняя длина поиска в одном пространстве составляет:
 .
.
Средняя величина считается по формуле:

Остаётся найти вероятность
 . Она равна
. Она равна  , где
, где  — число случаев, когда
— число случаев, когда  , и
, и  — общее число случаев. Не сложно догадаться, что
— общее число случаев. Не сложно догадаться, что 
Подставляем это в формулу для средней величины:
то есть,
 , где — высота дерева.
, где — высота дерева.Если перейти от высоты дерева к количеству элементов, то:
 , где
, где  — количество элементов в узле.
— количество элементов в узле.Из этого можно сделать вывод, что чем больше элементов будет содержаться в узле, тем быстрее будет проходить поиск по дереву, так как высота дерева будет оставаться минимальной, однако не следует хранить огромное количество элементов в узле, так как при таком способе всё дерево может выродиться в обычный массив или список.
Добавление элементов
Добавление элементов происходит точно так же как и в обычном двоичном дерево поиска, с той лишь разницей, что каждый уровень дерева будет определяться ещё и пространством к которому он относится.
Алгоритм продвижения по дереву:
for (int i = 0; tree; i++) // i - это номер пространства if (tree->x[i] < tree->t) // t - медиана tree = tree->left; // переходим в левое поддерево else tree = tree->right; // переходим в правое поддерево
Добавление выполняется за
, где — высота дерева.Удаление элементов
При удалении элементов дерева может возникнуть несколько ситуаций.
- Удаление листа дерева — довольно простое удаление, когда удаляется один узел, и указатель узла-предка просто обнуляется.
- Удаление узла дерева (не листа) — очень сложная процедура, при которой приходится перестраивать всё поддерево для данного узла.
Иногда процесс удаления узла решается модификациями k-d дерева. К примеру, если у нас в узле содержится массив элементов, то при удалении всего массива узел дерева остаётся, но новые элементы туда больше не записываются.
Поиск диапазона элементов
Поиск основан на обычном спуске по дереву, когда каждый узел проверяется на диапазон. Если медианы узла меньше или больше заданного диапазона в данном пространстве, то обход идет дальше по одной из ветвей дерева. Если же медиана узла входит полностью в заданный диапазон, то нужно посетить оба поддерева.
- Алгоритм
Z – узел дерева [(x_0_min, x_1_min, x_2_min,..., x_n_min),(x_0_max, x_1_max, x_2_max,..., x_n_max)] - заданный диапазон Функция Array(Node *&Z){ If ([x_0_min, x_1_min, x_2_min,..., x_n_min]<Z){ Z=Z->left; // левое поддерево } else If ([x_0_max, x_1_max, x_2_max,..., x_n_max]>Z){ Z=Z->right; // правое поддерево } Else{ // просмотреть оба поддерева Array(Z->right); // запустить функцию для правого поддерева Z=Z->left; // просмотреть левое поддерево } }
- Анализ
Очевидно, что минимальное количество просмотренных элементов это
, где — высота дерева. Так же очевидно, что максимальное количество просмотренных элементов это  , то есть просмотр всех элементов дерева. Остаётся посчитать среднее количество просмотренных элементов .
, то есть просмотр всех элементов дерева. Остаётся посчитать среднее количество просмотренных элементов .![[(x_{0_{min}}, x_{1_{min}}, x_{2_{min}},..., x_{n_{min}}),(x_{0_{max}}, x_{1_{max}}, x_{2_{max}},..., x_{n_{max}})]](5b4c1127617dab7c993cf231ef93ac5b.png) — заданный диапозон.
— заданный диапозон.Оригинальная статья про k-d деревья даёт такую характеристику:
 для фиксированного диапазона.
для фиксированного диапазона.Если перейти высоты дерева к количеству элементов, то это будет:

Поиск ближайшего соседа
Поиск ближайшего элемента состоит из 2-х задачек. Определение возможного ближайшего элемента и поиск ближайших элементов в заданном диапазоне, то есть
Дано дерево
 . Мы спускаемся по дереву к его листьям по условию
. Мы спускаемся по дереву к его листьям по условию tree\to t](38ac177dac77da365098bf55e7828805.png) и определяем вероятный ближайший элемент по условию
и определяем вероятный ближайший элемент по условию ![l_{min}=\sqrt{(({x_0-x[i]_0})^2 + ({x_1-x[i]_1})^2 + ... + ({x_n-x[i]_n})^2)}](c3b48a3c226199841a7a85063bfda615.png) . После этого от корня дерева запускается алгоритм поиска ближайшего элемента в заданном диапазоне, который определяется радиусом
. После этого от корня дерева запускается алгоритм поиска ближайшего элемента в заданном диапазоне, который определяется радиусом ![R=l_{min}=\sqrt{(({x_0-x[i]_0})^2 + ({x_1-x[i]_1})^2 + ... + ({x_n-x[i]_n})^2)}](117b6442175ba6a0d887e0c55ea949ba.png) .
.При этом при нахождении более близкого элемента корректируется радиус поиска.
- Алгоритм
Z – корень дерева| List – список ближайших элементов| [x_0,x_1,x_2...,x_n] - элемент для которого ищется ближайшие Len – минимальная длина Функция Maybe_Near(Node *&Z){ // поиск ближайшего возможного элемента While(Z){ // проверка элементов в узле for(i=0;i<N;i++){ len_cur=sqrt((x_0-x[i]_0)^2 + (x_1-x[i]_1)^2 + ... + (x_n-x[i]_n)^2); // длина текущего элемента if(Len>длины текущего элемента){ Len=len_cur; // установление новой длины Delete(List); // очистка списка Add(List); // добавить новый элемент в список } Else if(длины равны) Add(List); // добавить новый элемент в список If((x_0=x[i]_0) && (x_1=x[i]_1) && ... && (x_n=x[i]_n)) Return 1; } If([x_0,x_1,x_2...,x_n]<Z) Z=Z->left; // левое поддерево If([x_0,x_1,x_2...,x_n]>Z) Z=Z->right; // правое поддерево } } Функция Near(Node *&Z){ // поиск наиближайшего элемента в заданном диапазоне While(Z){ // проверка элементов в узле for(i=0;i<N;i++){ len_cur=sqrt((x_0-x[i]_0)^2 + (x_1-x[i]_1)^2 + ... + (x_n-x[i]_n)^2); // длина текущего элемента if(Len>длины текущего элемента){ Len=len_cur; // установление новой длины Delete(List); // очистка списка Add(List); // добавить новый элемент в список } Else if(длины равны) Add(List); // добавить новый элемент в список } If([x_0,x_1,x_2...,x_n]+len>Z){ // если диапазон больше медианы Near(Z->right); // просмотреть оба дерева Z=Z->left; } If([x_0,x_1,x_2...,x_n]<Z) Z=Z->left; // левое поддерево If([x_0,x_1,x_2...,x_n]>Z) Z=Z->right; // правое поддерево } }
- Анализ
Очевидно, что минимальное количество просмотренных элементов это
, где h — это высота дерева. Так же очевидно, что максимальное количество просмотренных элементов это , то есть просмотр всех узлов. Остаётся посчитать среднее количество просмотренных элементов.![[(x_0, x_1, x_2,..., x_n)]](59814cfd32a9798472bfb9d733f3f32b.png) — заданный элемент, относительно которого нужно найти ближайший. Эта задачка разбивается на 2. Нахождения ближайшего элемента в узле и нахождения ближайшего элемента в заданном диапазоне. Для первой части потребуется один спуск по дереву, то есть .
— заданный элемент, относительно которого нужно найти ближайший. Эта задачка разбивается на 2. Нахождения ближайшего элемента в узле и нахождения ближайшего элемента в заданном диапазоне. Для первой части потребуется один спуск по дереву, то есть .Для второй части, как мы уже вычислили, поиск элементов в заданном диапазоне равен
 . Что бы узнать среднее достаточно просто сложить эти 2 величины:
. Что бы узнать среднее достаточно просто сложить эти 2 величины: .
.См. также
Примечания
Ссылки
- libkdtree++, an open-source STL-like implementation of k-d trees in C++.
- A tutorial on KD Trees
- FLANN and its fork nanoflann, efficient C++ implementations of k-d tree algorithms.
- kdtree A simple C library for working with KD-Trees
- K-D Tree Demo, Java applet
- libANN Approximate Nearest Neighbour Library includes a k-d tree implementation
- Caltech Large Scale Image Search Toolbox: a Matlab toolbox implementing randomized k-d tree for fast approximate nearest neighbour search, in addition to LSH, Hierarchical K-Means, and Inverted File search algorithms.
- Heuristic Ray Shooting Algorithms, pp. 11 and after
- Into contains open source implementations of exact and approximate (k)NN search methods using k-d trees in C++.

Для улучшения этой статьи желательно?: - Найти и оформить в виде сносок ссылки на авторитетные источники, подтверждающие написанное.
- Проставив сноски, внести более точные указания на источники.
- Переработать оформление в соответствии с правилами написания статей.
- Викифицировать статью.
- Проверить статью на грамматические и орфографические ошибки.
- Исправить статью согласно стилистическим правилам Википедии.
Дерево (структура данных) Двоичное дерево поиска · Дерево (теория графов) · Древовидная структура Двоичные деревья Двоичное дерево · T-дерево Самобалансирующиеся двоичные деревья АА-дерево · АВЛ-дерево · Красно-чёрное дерево · Расширяющееся дерево · Дерево со штрафами · Декартово дерево · Дерево Фибоначчи B-деревья B-дерево · 2-3-дерево · B+ дерево · B*-дерево · UB-дерево · 2-3-4 дерево · (a,b)-дерево · Танцующее дерево Префиксные деревья Суффиксное дерево · Radix tree · Ternary search tree Двоичное разбиение пространства k-мерное дерево · VP-дерево Недвоичные деревья Дерево квадрантов · Октодерево · Sparse Voxel Octree · Экспоненциальное дерево · PQ-дерево Разбиение пространства R-дерево · R+-дерево · R*-дерево · X-дерево · M-дерево · Дерево Фенвика · Дерево отрезков Другие деревья Куча · TTH · Finger tree · Metric tree · Cover tree · BK-tree · Doubly-chained tree · iDistance · Link-cut tree Алгоритмы Поиск в ширину · Поиск в глубину · DSW-алгоритм · Алгоритм связующего дерева Структуры данных (список) Типы Массивы Ассоциативный массив • Multimap • Множество • Мультимножество • Хеш-таблица
Списки Деревья Графы Категории:- Деревья (структуры данных)
- Алгоритмы
![find(t_1): [(x_0=t_1)]; A=1.](23c41c669e9c7384a9f61603f9610182.png)
![find(t_2): [(x_0<t_1)\land(x_0=t_2)]; A=2.](8984a50a2d0c203e4b9eab4129c6e5ab.png)
![find(t_3): [(x_0>t_1)\land(x_0=t_3)]; A=2.](aba79f9aef9f2f45868aec6316fee4e1.png)
![find(t_4): [(x_0<t_1)\land(x_0<t_2)\land(x_0=t_4)]; A=3.](bea4e381774319c053e213ca644517e1.png)
![find(t_5): [(x_0<X_1)\land(x_0>t_2)\land(x_0=t_5)]; A=3.](ff0e107ce1b9d39a8f5f92ef9f48b99e.png)
![find(t_6): [(x_0<t_1)\land(x_0<t_3)\land(x_0=t_6)]; A=3.](2ae58bb59f1d251e77a3b7e626cecbeb.png)
![find(t_7): [(x_0<t_1)\land(x_0>t_3)\land(x_0=t_7)]; A=3.](e667105cba19ed67a2c20fc14ab6c4a0.png)





Wikimedia Foundation. 2010.